Nvidia ha presentado Nemotron-4 340B, una familia de modelos de lenguaje de código abierto diseñados para generar datos sintéticos de alta calidad y crear aplicaciones de inteligencia artificial (IA) poderosas en diversas industrias. Estos modelos prometen transformar la forma en que se entrenan los modelos de lenguaje de gran escala (LLM).
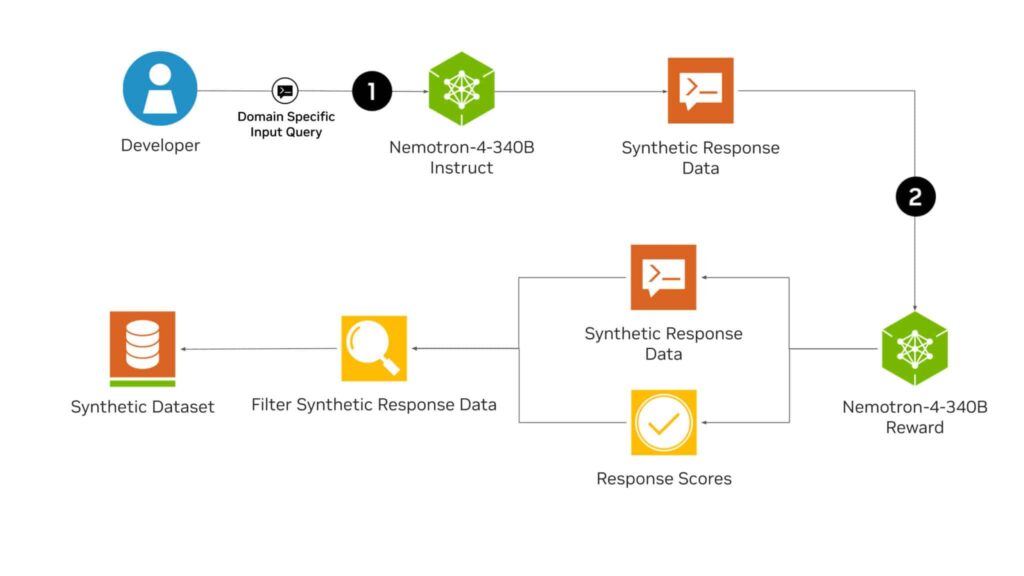
La familia Nemotron-4 340B incluye tres modelos principales: Base, Instruct y Reward, que forman una «tubería» para la creación de datos sintéticos utilizados en el entrenamiento de nuevos y poderosos LLM. El modelo Instruct crea datos de entrenamiento sintéticos de alta calidad, habiendo sido entrenado en un 98% con datos sintéticos, mientras que el modelo Reward filtra los datos para seleccionar los ejemplos de mayor calidad.
Estos modelos no solo igualan, sino que superan a competidores de código abierto como Llama-3, Mixtral y Qwen-2 en una variedad de evaluaciones. Además, Nvidia ha lanzado Mamba-2 Hybrid, un modelo de espacio de estado selectivo (SSM) que ha superado a modelos similares basados en transformadores en términos de precisión.
Nvidia proporciona así una familia de modelos gratuitos y de código abierto que no solo rivalizan con las capacidades de los principales competidores en el campo, sino que también destacan en la creación de datos sintéticos necesarios para mejorar continuamente los nuevos LLM. Este lanzamiento reafirma el estatus de Nvidia como una potencia en el ámbito de la IA.
Lanzamiento del pipeline de generación de datos sintéticos para el entrenamiento de LLM
Nemotron-4 340B, optimizado para Nvidia NeMo y Nvidia TensorRT-LLM, incluye modelos instructivos y de recompensa de última generación, y un conjunto de datos para el entrenamiento de IA generativa. Este lanzamiento permite a los desarrolladores generar datos sintéticos para entrenar LLM para aplicaciones comerciales en sectores como la salud, finanzas, manufactura, comercio minorista y más.
Los datos de entrenamiento de alta calidad son cruciales para el rendimiento y precisión de los LLM personalizados, pero obtener conjuntos de datos robustos puede ser costoso y difícil. Con una licencia de modelo abierto altamente permisiva, Nemotron-4 340B ofrece a los desarrolladores una forma gratuita y escalable de generar datos sintéticos para construir LLM potentes.
Generación de datos sintéticos con Nemotron-4 340B
Los LLM pueden ayudar a los desarrolladores a generar datos de entrenamiento sintéticos en situaciones donde el acceso a grandes y diversos conjuntos de datos etiquetados es limitado. El modelo Instruct de Nemotron-4 340B crea datos sintéticos diversos que imitan las características de datos del mundo real, mejorando la calidad de los datos para aumentar el rendimiento y robustez de los LLM personalizados en diversos dominios.
Para mejorar la calidad de los datos generados por IA, los desarrolladores pueden utilizar el modelo Reward de Nemotron-4 340B para filtrar las respuestas de alta calidad. Este modelo evalúa las respuestas según cinco atributos: utilidad, corrección, coherencia, complejidad y verbosidad. Actualmente, ocupa el primer lugar en la tabla de clasificación RewardBench de Hugging Face, creada por AI2, para evaluar las capacidades, seguridad y riesgos de los modelos de recompensa.
Optimización y seguridad de los modelos
Utilizando NeMo y TensorRT-LLM de Nvidia, los desarrolladores pueden optimizar la eficiencia de sus modelos instructivos y de recompensa para generar datos sintéticos y evaluar respuestas. Todos los modelos de Nemotron-4 340B están optimizados con TensorRT-LLM para aprovechar el paralelismo de tensores, permitiendo una inferencia eficiente a escala.
El modelo Base de Nemotron-4 340B, entrenado con 9 billones de tokens, puede personalizarse utilizando el marco NeMo para adaptarse a casos de uso específicos. Este proceso de ajuste fino beneficia de datos de preentrenamiento extensivos y produce salidas más precisas para tareas específicas.
Nvidia ha asegurado que el modelo Instruct de Nemotron-4 340B ha pasado por una evaluación de seguridad exhaustiva, incluyendo pruebas adversarias, y ha demostrado un buen rendimiento en una amplia gama de indicadores de riesgo. No obstante, se recomienda a los usuarios evaluar cuidadosamente las salidas del modelo para garantizar que los datos generados sean adecuados, seguros y precisos para su uso.
Los modelos Nemotron-4 340B están disponibles para descarga en Hugging Face, y los desarrolladores podrán acceder a ellos pronto en ai.nvidia.com, empaquetados como un microservicio NVIDIA NIM con una API estándar que puede desplegarse en cualquier lugar.
Conclusión
Con el lanzamiento de Nemotron-4 340B, Nvidia reafirma su compromiso con el desarrollo y accesibilidad de tecnologías de inteligencia artificial avanzadas. Estos modelos de código abierto no solo facilitan la generación de datos sintéticos de alta calidad, sino que también posicionan a Nvidia a la vanguardia de la innovación en IA, ofreciendo herramientas poderosas y escalables para desarrolladores en todo el mundo.
Más información en blogs Nvidia.













