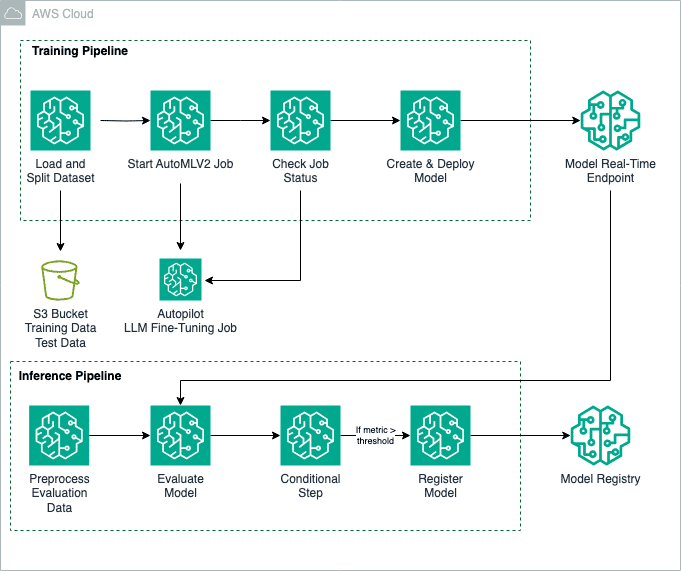
En el ámbito de la inteligencia artificial, la mejora de modelos base a través del ajuste fino se ha consolidado como una técnica esencial para optimizar su capacidad de comprensión y precisión en distintos dominios. Un reciente experimento ha resaltado la eficacia de este enfoque, utilizando Amazon SageMaker Autopilot junto con el SDK AutoMLV2 para perfeccionar un modelo Meta Llama2-7B en tareas de respuesta a preguntas, especialmente en exámenes de ciencias que abarcan física, química y biología.
Este proceso de ajuste no solo se limita a tareas de preguntas y respuestas, sino que también es aplicable en áreas como la generación de resúmenes o la creación de textos en sectores como la atención médica, la educación o los servicios financieros. La funcionalidad de AutoMLV2 facilita la instrucción y ajuste de una variedad de modelos mediante Amazon SageMaker JumpStart. A lo largo de las diferentes etapas del flujo de trabajo, que incluyen la preparación de datos, el ajuste del modelo y su creación, se emplea Amazon SageMaker Pipelines para automatizar cada paso.
El método utilizado implica el uso del conjunto de datos SciQ, un repositorio especializado en preguntas de examen de ciencias, para entrenar el modelo Llama2-7B. Los datos son estructurados en archivos CSV que contienen columnas de entradas y salidas; las entradas configuran el prompt y las salidas incluyen las respuestas correctas, asegurando así la compatibilidad con SageMaker Autopilot.
La configuración del ajuste fino requiere la especificación de ciertos parámetros, como el nombre del modelo base, la aceptación de los contratos de licencia del usuario final (EULA), y diversos hiperparámetros como el número de épocas y la tasa de aprendizaje, que se afinan para adaptar el modelo a las necesidades específicas del problema.
Una vez que el modelo ha sido afinado, se despliega en un punto de inferencia en tiempo real, lo que permite obtener resultados inmediatos. La biblioteca fmeval se utiliza para evaluar exhaustivamente estos modelos, ofreciendo una evaluación detallada basada en métricas personalizadas y asegurando el correcto desempeño del modelo en ambientes reales.
Este enfoque no solo incrementa la precisión en las tareas asignadas, sino que también optimiza la implementación y la evaluación, simplificando considerablemente el despliegue de modelos en plataformas de producción. Se establece además un control riguroso de calidad mediante la evaluación de métricas de rendimiento, asegurando que únicamente los modelos de alto rendimiento sean registrados y desplegados.
En resumen, este flujo automatizado marca un avance significativo hacia una implementación más eficiente de modelos de lenguaje de gran escala, facilitando su integración en sistemas que requieren inferencias en tiempo real con altos niveles de precisión y relevancia.














