La Inteligencia Artificial local vive un momento de auge, pero también de bastante confusión. Cada semana aparecen nuevos modelos, nuevas cuantizaciones y nuevas promesas sobre lo que puede ejecutarse “sin problemas” en un portátil, un sobremesa o un Mac con Apple Silicon. En medio de ese ruido ha empezado a ganar visibilidad CanIRun.ai, una web que intenta responder a una pregunta cada vez más común entre desarrolladores y usuarios avanzados: qué modelos de IA puede mover realmente una máquina concreta y con qué nivel de rendimiento. La propuesta es sencilla de entender: detectar el hardware desde el navegador, cruzarlo con una base de modelos y mostrar cuáles “van bien”, cuáles entran justos y cuáles son directamente inviables.
La clave está en que la herramienta no se presenta como un benchmark tradicional ni como un simple catálogo de modelos. Su planteamiento es más pragmático. CanIRun.ai calcula estimaciones en local, dentro del propio navegador, usando APIs web para identificar GPU, CPU y memoria, y después aplica una fórmula de puntuación que combina velocidad estimada, margen de memoria y un pequeño extra por tamaño o calidad potencial del modelo. Todo ello, además, sin enviar esos datos a un servidor, según explica la propia página “Why” del servicio.
No es un detalle menor. En un momento en el que la IA en local se ha convertido en una alternativa real para muchos usuarios que quieren privacidad, menor dependencia de la nube o simplemente reducir costes, la barrera ya no es solo instalar Ollama, LM Studio o llama.cpp. El gran problema pasa por saber si un modelo concreto cabe en la VRAM disponible, si el contexto elegido lo vuelve impracticable o si el rendimiento será tan bajo que la experiencia acabará siendo frustrante. Ahí es donde CanIRun.ai intenta aportar algo útil: menos marketing de modelos y más realidad de hardware.
Cómo detecta el hardware y por qué sus cifras son solo orientativas
Según explica el propio sitio, la detección se apoya en tres fuentes principales. Para identificar la GPU utiliza WebGL y, en concreto, la extensión WEBGL_debug_renderer_info, que permite recuperar el nombre del renderizador gráfico. Si el navegador soporta WebGPU, también intenta extraer más detalles del adaptador, incluidos datos sobre el dispositivo y su arquitectura. Para CPU y RAM usa navigator.hardwareConcurrency y navigator.deviceMemory, además de una pequeña prueba local para estimar el rendimiento mononúcleo. Todo el proceso se ejecuta en el cliente, sin instalación de extensiones ni software adicional.
Ahora bien, la propia web insiste en que los resultados son estimaciones, no garantías. Y es importante subrayarlo. Las APIs del navegador ofrecen información limitada: la RAM puede aparecer redondeada, la GPU puede identificarse con cadenas ambiguas y el ancho de banda de memoria no se mide en tiempo real, sino que se toma de bases de datos construidas a partir de especificaciones públicas. A eso se suman variables que la página no puede conocer desde el navegador, como la temperatura del equipo, la presión de memoria del sistema operativo, la versión de drivers, procesos en segundo plano o limitaciones energéticas del portátil. Dicho de forma simple: CanIRun.ai sirve para orientar bien, pero no sustituye una prueba real en el entorno del usuario.
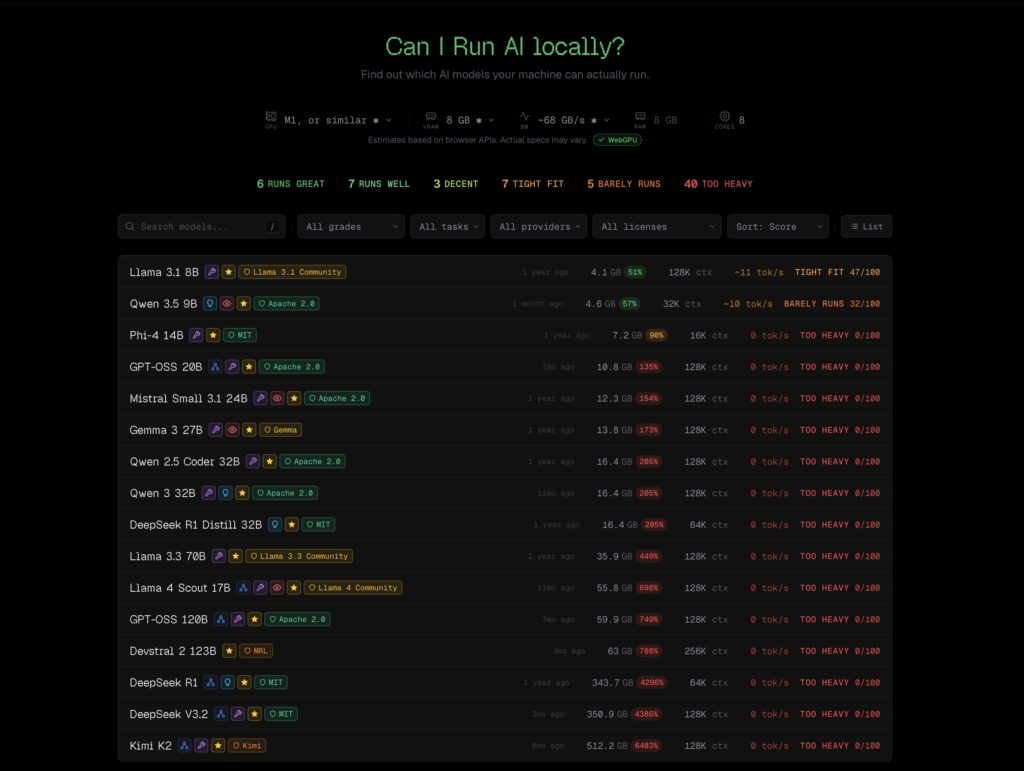
La herramienta también documenta cómo estima la memoria necesaria para cada modelo. Su fórmula parte del número de parámetros, los bits por peso y un pequeño sobrecoste para caché KV y buffers de ejecución. A partir de ahí crea una jerarquía de cuantizaciones —desde Q2_K hasta F16— y calcula cuánta VRAM pediría cada una. Por ejemplo, la propia documentación resume que un modelo de 70.000 millones de parámetros en Q4_K_M necesita alrededor de 35 GB más una pequeña sobrecarga adicional. Ese tipo de aproximación no es nuevo en el mundo de la IA local, pero aquí se presenta de forma bastante transparente y accesible para el usuario medio.
La puntuación mezcla velocidad, margen y tamaño del modelo
Uno de los elementos más interesantes del proyecto es su sistema de puntuación. CanIRun.ai dice combinar tres factores: la velocidad estimada en tokens por segundo, con un peso del 55 %; el margen de memoria disponible, con un 35 %; y un bonus de calidad de alrededor del 10 %, pensado para no castigar en exceso a los modelos algo más grandes. Además, introduce una penalización adicional cuando el modelo entra en la categoría “tight”, es decir, cuando cabe de forma muy ajustada y el margen real para contexto, batching u otros procesos es escaso.
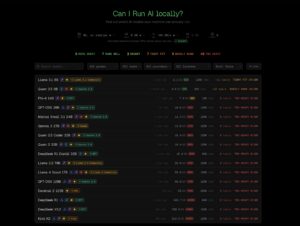
El resultado final se traduce en una escala bastante comprensible para cualquiera: Runs great, Runs well, Decent, Tight fit, Barely runs o Too heavy. Esa taxonomía puede parecer simple, pero probablemente ahí está parte del acierto del sitio. Frente a tablas técnicas llenas de parámetros, cuantizaciones y matices difíciles de interpretar, CanIRun.ai aterriza el problema en una pregunta muy humana: “¿me merece la pena intentar correr este modelo en mi máquina?”. Para quien está dando sus primeros pasos en IA local, ese enfoque tiene más valor del que parece.
El caso de Apple Silicon merece además un tratamiento específico dentro de la herramienta. La web explica que en los Mac con memoria unificada CPU y GPU comparten el mismo pool, por lo que puede aprovecharse hasta aproximadamente el 75 % de la RAM total para inferencia. Eso permite que determinados equipos de Apple ejecuten modelos que serían imposibles en un PC con una GPU discreta de 8 GB o 12 GB, aunque también conlleva un comportamiento distinto en latencia y presión de memoria. CanIRun.ai incorpora ese matiz en sus cálculos y lo explica de forma explícita en su documentación.
Una utilidad con sentido en un mercado saturado de promesas
Más allá del detalle técnico, la aparición de herramientas como CanIRun.ai dice bastante sobre el momento que vive la IA local. Hasta hace poco, la conversación giraba sobre qué modelo era “mejor”. Ahora la pregunta real es otra: cuál es el mejor modelo que cada usuario puede ejecutar de forma razonable en su propio hardware. Esa diferencia cambia por completo el enfoque. Ya no basta con hablar de benchmarks máximos o de parámetros; hace falta hablar de viabilidad, consumo de memoria, velocidad de lectura de pesos y experiencia real.
CanIRun.ai no resuelve por sí sola todos esos problemas, pero sí cubre una necesidad concreta con bastante claridad. Ofrece una capa de orientación rápida, privada y sin instalación, documenta de dónde salen sus números y deja claro que trabaja con estimaciones. En un ecosistema donde abundan más las promesas que las advertencias, ese tono resulta casi refrescante. Y quizá por eso está encontrando su hueco dentro de la comunidad que explora la IA en local: no promete milagros, pero sí ayuda a evitar unas cuantas decepciones.
Preguntas frecuentes
¿CanIRun.ai mide el rendimiento real de un modelo en mi PC?
No exactamente. La propia web explica que trabaja con estimaciones calculadas en el navegador a partir de APIs web, una base de GPUs y fórmulas sobre VRAM, ancho de banda y cuantización. Sirve como orientación, pero no sustituye una prueba real con el modelo ejecutándose en local.
¿Qué datos usa CanIRun.ai para detectar el hardware?
Usa WebGL para identificar la GPU, WebGPU si está disponible para obtener más detalles del adaptador, y las APIs navigator.hardwareConcurrency y navigator.deviceMemory para estimar CPU y RAM. También ejecuta una pequeña prueba local de CPU.
¿Por qué un Mac con Apple Silicon puede mover modelos que un PC con una GPU modesta no puede?
Porque, según explica la propia herramienta, Apple Silicon usa memoria unificada compartida entre CPU y GPU, lo que permite reservar una parte mucho mayor de la RAM total para inferencia que la VRAM fija de una GPU discreta convencional.
¿Qué significan etiquetas como “Runs great” o “Tight fit”?
Son categorías que resumen el encaje estimado del modelo en el hardware detectado. “Runs great” implica buena velocidad y margen de memoria; “Tight fit” indica que el modelo entra muy justo; y “Too heavy” significa que, según el cálculo de la web, no debería ejecutarse de forma usable en esa máquina.