En el actual panorama de la inteligencia artificial, los modelos de lenguaje grandes (LLMs) han logrado un notable éxito en diversas tareas de procesamiento del lenguaje natural (NLP). Sin embargo, estos modelos no siempre se adaptan de manera óptima a dominios o tareas específicas. Surge así la necesidad de personalizar un LLM para adecuarlo a casos de uso únicos, mejorando su rendimiento en datasets o tareas específicas. Esta personalización puede lograrse mediante ingeniería de prompts, Generación Aumentada por Recuperación (RAG) o ajuste fino. Es crucial evaluar un LLM personalizado frente al modelo base (u otros modelos) para asegurar que el proceso de personalización efectivamente mejore su rendimiento en la tarea específica.
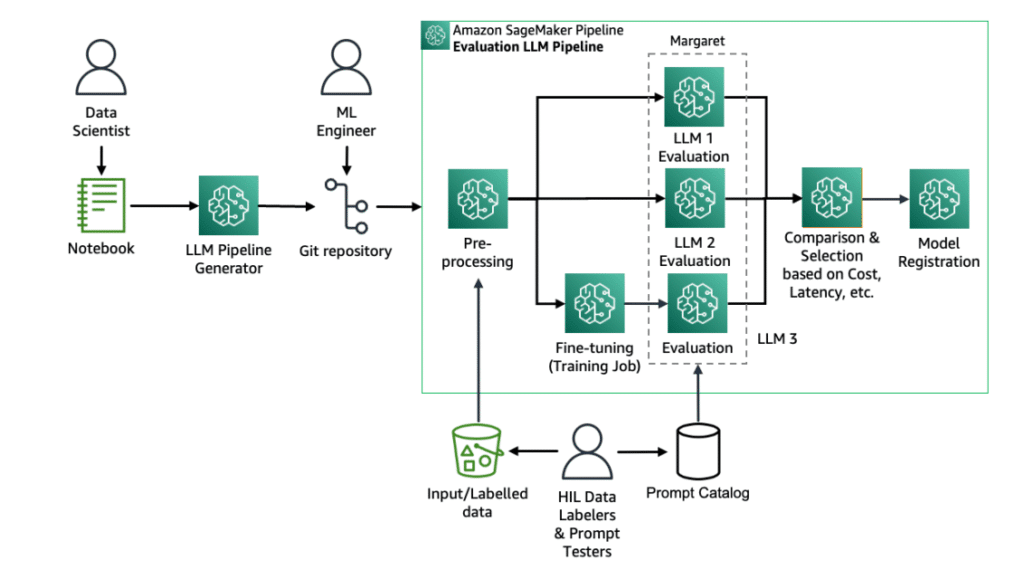
La personalización a través del ajuste fino de LLMs es un procedimiento complejo que involucra múltiples experimentos y combinaciones de datasets, hiperparámetros, prompts y técnicas de ajuste fino como el ajuste fino de parámetros eficientes (PEFT). Cada iteración en un experimento puede ser considerada como una ejecución independiente.
Para simplificar este proceso, Amazon SageMaker, en combinación con MLflow y SageMaker Pipelines, ofrece herramientas para el ajuste fino y la evaluación a escala. Estas plataformas permiten gestionar múltiples experimentos, comparar los resultados y seguir el ciclo de vida del aprendizaje automático (ML), desde la preparación de datos hasta el despliegue del modelo.
Antes de comenzar con la personalización, es fundamental tener ciertos prerrequisitos como el token de acceso a Hugging Face y los permisos necesarios en SageMaker. Con estas herramientas configuradas, el proceso de personalización incluye la selección del modelo base adecuado y el ajuste fino mediante técnicas avanzadas como LoRA (Low-Rank Adaption).
El ajuste fino de un modelo Llama3 utilizando LoRA y rastreando los parámetros de entrenamiento con MLflow nos permite identificar los parámetros más efectivos para el dataset y la tarea específica. Los resultados de estos experimentos se pueden comparar utilizando SageMaker Pipelines y MLflow, lo cual facilita la identificación del mejor modelo para su despliegue.
El modelo final ajustado y evaluado se puede registrar en MLflow y sincronizar automáticamente con el Registro de Modelos de Amazon SageMaker. Posteriormente, este modelo puede ser desplegado utilizando la consola de SageMaker o el SDK de SageMaker.
Conclusiones:
En resumen, con el uso de SageMaker y MLflow, es posible ejecutar experimentos de ajuste fino y evaluación de LLMs a gran escala, comparar parámetros de entrenamiento y resultados de evaluación, y desplegar el modelo óptimo en un entorno de producción. La integración de MLflow en los flujos de trabajo de LLM proporciona una solución eficiente para gestionar el ciclo de vida del ML, desde la experimentación hasta la producción, garantizando reproducibilidad y eficiencia.
vía: AWS machine learning blog














{kind=link}