Durante años, millones de usuarios han vivido con una sensación de seguridad práctica: si se publica bajo un seudónimo —un throwaway en Reddit, un alias en un foro técnico, una cuenta secundaria para hablar de trabajo o de política—, lo normal es que nadie invierta tiempo en atar cabos. Ese “nadie va a molestarse” ha funcionado como una capa informal de privacidad. Un nuevo estudio académico sostiene que esa capa se está rompiendo.
El trabajo, titulado Large-scale online deanonymization with LLMs, está firmado por investigadores vinculados a ETH Zurich, Anthropic y MATS, y defiende que los modelos de lenguaje de gran tamaño —la misma tecnología que hoy se usa para resumir textos o programar— permiten automatizar ataques de desanonimización a una escala y con un coste que antes estaban reservados a investigaciones manuales y selectivas. 2602.16800v2
De la “oscuridad práctica” al buscador automático de identidades
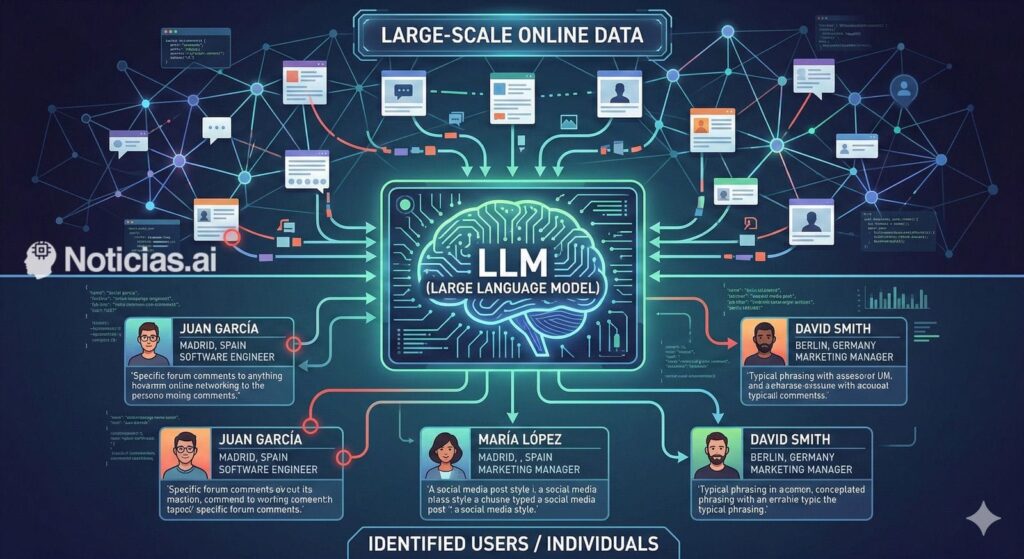
La idea central es sencilla, pero inquietante: la desanonimización suele tener dos pasos. Primero, perfilar a una persona a partir de sus publicaciones (intereses, profesión, ubicación, hábitos, forma de expresarse, temas recurrentes). Segundo, encontrar una identidad real que encaje con ese perfil, comparando contra bases de datos o huellas públicas en la web.
Lo novedoso, según el estudio, no es que aparezcan “señales mágicas” que antes no existieran. Es la economía del proceso. Los autores describen a los modelos de lenguaje como un “microscopio de información” que convierte en rutinario lo que antes era trabajo artesanal: extraer microdetalles, buscar candidatos entre miles o millones de perfiles y razonar si el encaje es sólido o si conviene abstenerse. 2602.16800v2
En la práctica, eso cambia el equilibrio: lo que antes requería horas de un investigador motivado puede resolverse en minutos con un flujo automatizado, siempre apoyándose en contenido ya público: comentarios, biografías, historiales de participación y referencias cruzadas.
Qué probaron y qué cifras reportan
El artículo distingue varios escenarios y, en todos, intenta medir el éxito con métricas de precisión y recall (recuperación). Para evitar daños directos, no “cazan” cuentas realmente anónimas al azar: construyen conjuntos con verdad de referencia (por ejemplo, perfiles que ya enlazaban públicamente a otra plataforma y que luego son “anonimizados” para comprobar si el sistema puede recuperar el enlace borrado). 2602.16800v2
En su demostración más llamativa de “agente con Internet” —un modelo que busca en la web, cruza fuentes y propone identidades— reportan resultados de 25 % a 67 % de recall con 70 % a 90 % de precisión en perfiles de Hacker News y Reddit, replicando en minutos lo que podría llevar horas a una investigación manual. 2602.16800v2
En un conjunto de 338 usuarios de Hacker News que habían enlazado su LinkedIn en la biografía (la identidad real está verificada por ese enlace), el agente identifica correctamente a 226: 67 % de recall con 90 % de precisión (con abstenciones cuando no estaba suficientemente seguro). 2602.16800v2
El estudio también aborda el caso de transcripciones “anonimizadas” del Anthropic Interviewer dataset, una colección pública de entrevistas sobre el uso de Inteligencia Artificial en investigación. En una muestra, el sistema llega a identificar 9 de 33 perfiles probados (con errores y abstenciones), subrayando que incluso textos parcialmente redactados pueden contener suficiente contexto como para reconstruir pistas externas. 2602.16800v2
En los experimentos no todo es “éxito masivo”: cuando el contenido compartido es menos distintivo, el recall cae. Por ejemplo, al intentar vincular usuarios entre comunidades de cine en Reddit, el rendimiento es menor; aun así, los autores destacan un patrón relevante: cuanto más “microdato” repetido (películas concretas, gustos, detalles específicos), más fácil resulta el emparejamiento. 2602.16800v2
Cómo funciona el “pipeline” sin entrar en instrucciones operativas
La investigación descompone el ataque en una cadena modular que mezcla extracción, búsqueda y verificación:
- Extraer señales: el modelo convierte texto desordenado (posts y comentarios) en un perfil de rasgos (temas recurrentes, demografía inferida, ubicaciones, habilidades, hábitos).
- Buscar candidatos: esas señales se transforman en representaciones semánticas que permiten rastrear perfiles parecidos en un gran conjunto.
- Razonar y verificar: un modelo más potente compara el “top” de candidatos, busca coherencias y contradicciones, y decide si hay match.
- Calibrar: el sistema ajusta umbrales para “apostar” solo cuando la probabilidad de error es baja y, si no, abstenerse. 2602.16800v2
Una lectura importante del propio estudio es que muchas defensas clásicas no atacan el núcleo del problema. Limitar peticiones, poner barreras de uso o introducir “guardrails” puede frenar abusos obvios, pero el pipeline se construye con tareas que, por separado, parecen benignas: resumir texto, calcular similitudes, ordenar resultados. 2602.16800v2
El coste y la nueva amenaza para usuarios normales
En términos económicos, el trabajo pone números a algo que hasta hace poco se intuía. Ejecutar el agente por perfil, según sus pruebas, cuesta 1–4 dólares por objetivo, y el total de sus experimentos se mantuvo por debajo de 2.000 dólares. 2602.16800v2
Ese dato es el que cambia el tono: no hace falta un “caso de alto valor” para justificar el esfuerzo. Si alguien quiere vincular cuentas, agrupar identidades secundarias o intentar “doxxing” selectivo, el umbral de entrada baja de forma dramática.
El propio artículo concluye con una frase que resume el giro de época: la seudonimia deja de ser una protección “significativa” cuando un adversario puede correlacionar actividad a gran escala. Y cuanto más persistente es el alias, más fácil es construir un perfil estable con el tiempo. 2602.16800v2
Qué se puede hacer (sin promesas falsas)
El estudio es pesimista con las soluciones fáciles, pero deja entrever el tipo de higiene digital que gana valor en este escenario:
- Reducir señales repetibles: detalles estables (ubicación concreta, empresa, nichos muy específicos, rutinas) son los que más ayudan a enlazar perfiles.
- Separar identidades de verdad: no basta con “otra cuenta” si se repiten temas, horarios, círculos o datos indirectos.
- Revisar el pasado: lo antiguo no desaparece; si sigue indexado, puede convertirse en evidencia auxiliar.
- Presionar a plataformas y proveedores: parte del riesgo se amplifica cuando hay acceso masivo a datos públicos, scraping fácil o APIs que facilitan correlaciones. 2602.16800v2
La conclusión práctica es incómoda, pero clara: la era del “nadie sabe quién soy” ya no depende solo de la intención del usuario, sino del coste de correlacionar datos. Y ese coste está cayendo.
Fuente: ArXiV