Elegir un modelo de Inteligencia Artificial para ejecutarlo en local se ha convertido en una tarea bastante menos trivial de lo que parece. No basta con fijarse en el número de parámetros o en la fama del modelo de turno. También importan la memoria RAM disponible, la VRAM de la GPU, el backend de aceleración, la cuantización y hasta el contexto que se quiere manejar. En ese terreno, donde muchos usuarios todavía prueban a ciegas hasta dar con algo que funcione, llmfit se está abriendo paso como una de las utilidades más prácticas del momento dentro del ecosistema open source. Su propuesta es directa: detectar el hardware del equipo, cruzarlo con una base de modelos y decir cuáles pueden ejecutarse de verdad con cierta solvencia.
El proyecto, desarrollado por Alex Jones y distribuido con licencia MIT, se presenta como una herramienta de terminal con interfaz TUI por defecto y modo CLI clásico. Su última versión estable publicada en GitHub es la 0.7.4, lanzada el 15 de marzo de 2026, y también figura ya en Homebrew como versión estable para macOS y Linux, además de ofrecer instalación en Windows mediante Scoop, contenedor Docker y compilación desde código fuente. No es un detalle menor: una parte de su rápido crecimiento tiene que ver precisamente con esa facilidad para ponerse en marcha en distintos entornos.
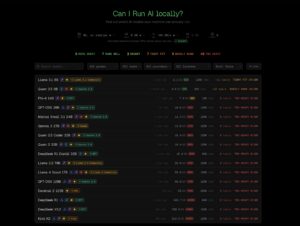
La idea de fondo llega en un momento oportuno. Con el auge de Ollama, llama.cpp, MLX y otros runtimes locales, cada vez más usuarios quieren ejecutar modelos en portátiles, estaciones de trabajo o servidores propios sin pasar por la nube. El problema es que el mercado está lleno de opciones y no siempre queda claro qué cabe realmente en una máquina concreta ni con qué calidad o rendimiento. Ahí es donde llmfit intenta poner orden: en vez de limitarse a listar modelos, puntúa cada uno en dimensiones como calidad, velocidad, ajuste a memoria y contexto, y los clasifica según el encaje con el hardware detectado.
Un recomendador técnico, no otro catálogo de modelos
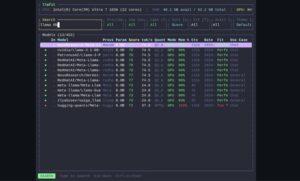
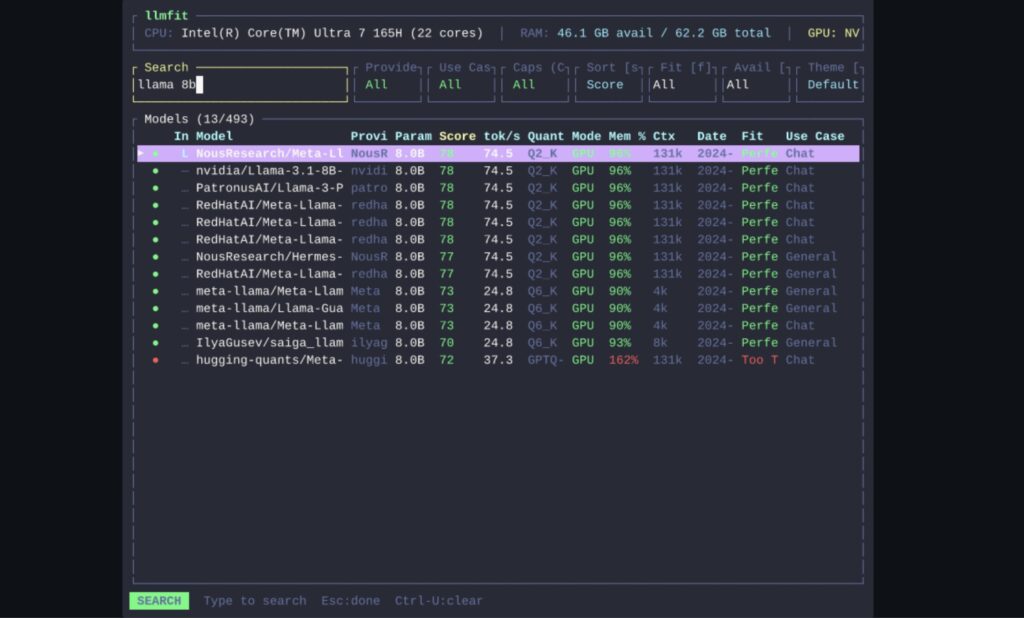
Lo que diferencia a llmfit de otras herramientas similares es que no se queda en la superficie. El proyecto explica que detecta RAM, CPU y GPU de forma automática, con soporte para NVIDIA, AMD, Intel Arc, Apple Silicon y Ascend, e identifica también el backend de aceleración disponible, desde CUDA hasta Metal, ROCm o CPU puro. A partir de ahí calcula el ajuste de cada modelo teniendo en cuenta cuantizaciones, consumo de memoria y modos de ejecución como GPU completa, CPU+GPU, CPU pura o arquitecturas Mixture-of-Experts con offloading parcial.
Ese matiz técnico es importante porque evita uno de los errores más frecuentes en la conversación sobre IA local: asumir que todos los modelos grandes se comportan igual. llmfit tiene en cuenta, por ejemplo, que un modelo MoE no activa todos sus expertos al mismo tiempo y que, por tanto, su carga real sobre la VRAM puede ser sensiblemente menor que la que sugiere el número total de parámetros. También elige de forma dinámica la mejor cuantización que cabe en el equipo, en lugar de dar por hecho una sola configuración fija. En términos prácticos, eso se traduce en recomendaciones más realistas para quien quiere saber si un modelo le va a funcionar bien o si solo “entra” en condiciones demasiado justas.
La herramienta tampoco se limita al uso interactivo en terminal. El proyecto incluye una vista TUI con filtros, comparativas, búsqueda, descarga directa de modelos y un modo de planificación que invierte la lógica habitual: en vez de preguntar “qué cabe en mi hardware”, permite estimar “qué hardware necesito para este modelo y este contexto”. Además, llmfit puede ejecutarse como una API REST a nivel de nodo mediante llmfit serve, una opción pensada para planificadores, agregadores o entornos donde interesa automatizar la selección del mejor modelo según el equipo disponible.
Por qué empieza a llamar tanto la atención
La tracción pública del proyecto ya no parece anecdótica. GitHub muestra más de 17.500 estrellas para el repositorio, mientras que Homebrew le atribuye 9.741 instalaciones en los últimos 30 días. Son cifras que, sin convertirlo todavía en un estándar de facto, sí indican que ha encontrado un hueco claro entre desarrolladores, usuarios avanzados y perfiles que trabajan con IA local a diario. Más aún en un contexto en el que muchos equipos combinan varios runtimes y varios proveedores según el caso de uso.
Buena parte de ese interés se explica por su enfoque híbrido entre utilidad para usuario final y pieza reutilizable para otros sistemas. llmfit soporta integración con Ollama, llama.cpp, MLX y Docker Model Runner; detecta qué modelos ya están instalados, permite descargar nuevos desde la propia TUI y mantiene mapeos entre nombres de Hugging Face y etiquetas de runtimes como Ollama. También incluye una skill para OpenClaw orientada a recomendar modelos adecuados al hardware y configurar proveedores locales. Dicho de otra forma: no solo sirve para consultar, también empieza a actuar como capa de decisión dentro de otros flujos de trabajo.
Ahora bien, conviene no venderlo como algo que no es. El propio repositorio aclara que llmfit estima rendimiento y ajuste a partir de detección de hardware, jerarquías de cuantización y fórmulas de throughput ligadas al ancho de banda de memoria. No ejecuta por defecto una batería real de benchmarks sobre cada modelo instalado. Esa diferencia importa, porque el resultado no sustituye una prueba empírica completa en producción. Sí sirve, en cambio, para reducir muchísimo el margen de error inicial y evitar descargas inútiles o expectativas poco realistas.
Un síntoma de hacia dónde va la IA local
Más allá del caso concreto de llmfit, su éxito ayuda a entender cómo está cambiando el mercado del software de IA local. Hace solo un año, buena parte de las conversaciones giraban alrededor de “qué modelo es mejor”. Ahora, cada vez más usuarios preguntan algo distinto: “qué modelo es mejor para mi máquina, mi presupuesto y mi caso de uso”. Ese cambio de enfoque, mucho más pragmático, favorece herramientas que no prometen milagros, sino compatibilidad razonable, planificación y decisiones más informadas.
En ese sentido, llmfit acierta al atacar un problema concreto y muy cotidiano: la distancia entre la promesa del modelo y la realidad del hardware. Puede parecer una utilidad menor frente a los grandes nombres del sector, pero en la práctica resuelve una fricción real para miles de usuarios que quieren ejecutar modelos localmente sin perder horas en ensayo y error. Y eso, en el ecosistema actual de la IA, ya es bastante más valioso de lo que parece.
Preguntas frecuentes
¿Qué hace exactamente llmfit?
llmfit detecta el hardware del equipo —RAM, CPU, GPU y backend— y clasifica modelos de lenguaje según calidad estimada, velocidad, ajuste a memoria y contexto, para indicar cuáles pueden ejecutarse bien en esa máquina.
¿llmfit ejecuta benchmarks reales de cada modelo?
No de forma general. Según la documentación del proyecto, estima el ajuste y la velocidad a partir del hardware detectado, la cuantización, el tamaño del modelo y fórmulas basadas en ancho de banda y modo de ejecución, por lo que actúa más como planificador y recomendador que como banco de pruebas exhaustivo.
¿Qué runtimes locales soporta llmfit?
El proyecto declara integración con Ollama, llama.cpp, MLX y Docker Model Runner, además de funciones para detectar instalaciones existentes y descargar modelos compatibles desde la propia interfaz.
¿Se puede usar llmfit más allá de la terminal interactiva?
Sí. Además del modo TUI y del modo CLI, llmfit puede exponerse como API REST con llmfit serve, algo útil para automatización, planificadores de nodos o herramientas que quieran recomendar modelos según el hardware disponible.
Más información GitHub llmfit