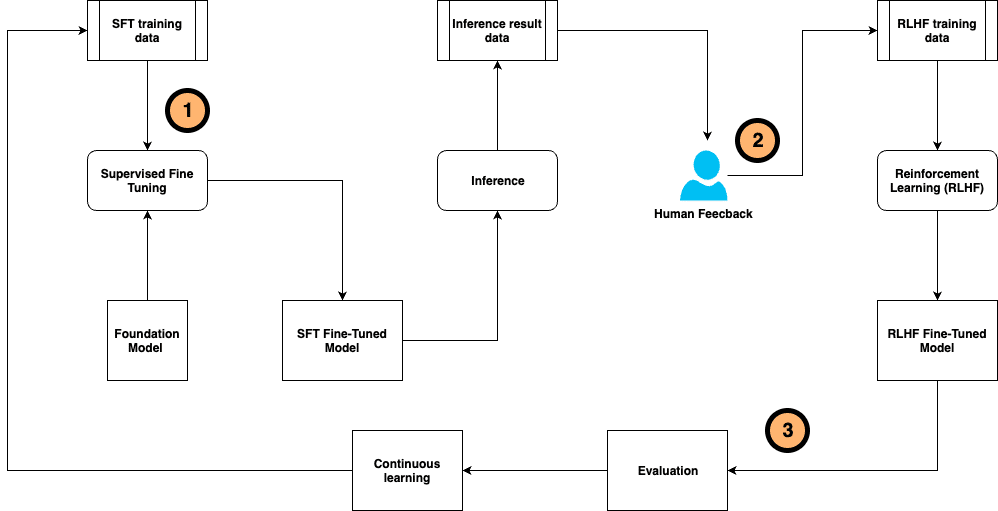
El ajuste fino de modelos de lenguaje grandes (LLM) preentrenados se ha convertido en una herramienta esencial para los usuarios que buscan personalizar estos modelos y optimizar su rendimiento en tareas específicas. Este proceso continuo permite que los modelos mantengan su precisión y eficacia, adaptándose a cambios en los datos y evitando la degradación del rendimiento con el tiempo. A través de esta técnica, es posible integrar retroalimentación humana, corregir errores y ajustar los modelos para aplicaciones del mundo real.
En este contexto, el ajuste fino supervisado (SFT) y la afinación de instrucciones juegan un papel crucial, utilizando conjuntos de datos y directrices anotadas por humanos. Cuando los modelos generan respuestas, el aprendizaje por refuerzo basado en la retroalimentación humana (RLHF) puede guiar sus salidas, recompensando aquellas alineadas con las preferencias humanas.
Sin embargo, alcanzar resultados precisos y responsables con los modelos LLM meticulosamente ajustados requiere un esfuerzo considerable de expertos. La anotación manual y la recolección de comentarios del usuario son tareas que demandan muchos recursos y tiempo. Además, coordinar el proceso continuo de ajuste fino, que incluye la generación de datos, entrenamiento del modelo, recolección de retroalimentación y alineación de preferencias, presenta un notable desafío.
Para enfrentar estos retos, se ha desarrollado un novedoso marco de ajuste fino auto-instruido continuo. Este sistema unifica la generación y anotación de datos de entrenamiento, el entrenamiento y evaluación del modelo, y la recolección de retroalimentación humana, alineando las preferencias de los usuarios. Este enfoque de inteligencia artificial compuesto tiene como objetivo mejorar la eficiencia en el perfeccionamiento del rendimiento, versatilidad y reutilización de modelos.
El marco propuesto opera de manera continua para adaptar el modelo base según muestras de entrenamiento etiquetadas por humanos y retroalimentación posterior a la inferencia. Este sistema multidimensional busca superar las restricciones de los modelos monolíticos tradicionales al fomentar la interacción entre múltiples componentes, incluyendo llamadas a diversos modelos, recuperadores y herramientas externas, todo para crear soluciones más complejas y eficientes.
Por otro lado, se ha introducido DSPy, un marco de programación en Python de código abierto que ofrece a los desarrolladores una base para construir aplicaciones LLM mediante programación modular y declarativa. DSPy está diseñado para optimizar tanto los resultados como la experiencia del usuario en aplicaciones de inteligencia artificial, brindando una mayor flexibilidad en el desarrollo y mantenimiento de soluciones.
En resumen, el sistema desarrollado para el ajuste fino continuo y auto-instruido no solo mejora la precisión y rendimiento de los modelos de lenguaje, sino que también establece un marco que maximiza la reutilización y adaptabilidad, enfrentando el cambio constante de los datos y las demandas de los usuarios.














