La creciente demanda de la inteligencia artificial generativa en el ámbito empresarial ha desencadenado una serie de innovaciones y soluciones innovadoras en las que empresas como Amazon están desempeñando un papel crucial. Una de las propuestas más prometedoras en este campo es el uso de modelos de lenguaje de gran tamaño preentrenados. Amazon ha presentado su plataforma, Amazon Bedrock, que facilita el acceso a modelos avanzados de diferentes startups de inteligencia artificial, así como de Amazon mismo, permitiendo a las empresas encontrar el modelo que mejor se adapte a sus necesidades específicas.
Amazon Bedrock no solo ofrece una amplia gama de modelos, sino que también permite su personalización, aspecto esencial para tareas avanzadas que requieren un enfoque especializado. La personalización se realiza a través del ajuste fino, un proceso que implica entrenar un modelo preentrenado utilizando datos etiquetados con precisión para optimizar su desempeño en escenarios específicos. Sin embargo, el desafío sigue siendo la recolección de datos relevantes y la garantía de su calidad en todo momento.
Como solución a este problema, ha surgido la generación de datos sintéticos. Esta técnica permite crear datos de entrenamiento artificiales, lo que resultó en un tiempo de respuesta más ágil y una disminución en la necesidad de grandes cantidades de recursos. Esto es particularmente beneficioso en situaciones donde los datos disponibles son escasos.
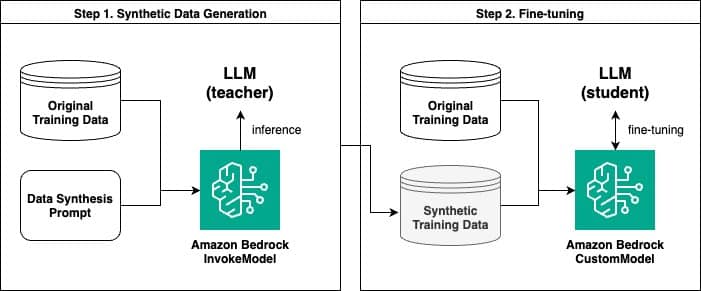
En este marco, Amazon Bedrock permite generar datos sintéticos y ajustar modelos de lenguaje a partir de estos datos. Un estudio reciente ilustró el proceso de generación de datos sintéticos con la API InvokeModel de Amazon Bedrock y el ajuste fino posterior con un modelo personalizado. Este método tiene dos etapas principales: primero se generan pares de preguntas y respuestas sintéticas mediante un modelo maestro, que luego se utilizan para entrenar un modelo más pequeño, conocido como modelo estudiante. Esta estrategia es similar a la destilación del conocimiento en aprendizaje profundo, demostrando mejorar significativamente el rendimiento del modelo.
Se llevaron a cabo evaluaciones comparativas para medir la efectividad de los modelos afinados con datos sintéticos frente a aquellos entrenados con datos originales. Los resultados indicaron que los modelos ajustados con datos sintéticos superaron en múltiples ocasiones a sus contrapartes, aunque no siempre en contextos donde había una cantidad suficiente de datos originales disponibles.
Además, se ha implementado una evaluación que utiliza un modelo de lenguaje como juez para valorar la calidad de las respuestas generadas por diferentes modelos. Los resultados de esta evaluación indicaron que los modelos afinados con ejemplos sintéticos mostraban un rendimiento excepcional.
En resumen, la utilización de Amazon Bedrock para generar datos sintéticos y personalizar modelos se presenta como una estrategia altamente efectiva para enfrentar la escasez de datos en diversas aplicaciones empresariales. A medida que las compañías buscan formas más eficaces y económicas de personalizar sus modelos de lenguaje, estas innovaciones están destinadas a desempeñar un papel clave en su desarrollo y éxito.













