Los recientes avances en modelos de inteligencia artificial generativa han impulsado un interés creciente en la creación de contenido multimedia de alta calidad. La clave para distinguir un contenido bueno de uno excepcional radica en los pequeños detalles que solo el feedback humano puede detectar. La segmentación de audio y video se presenta como un método estructurado para recopilar esta retroalimentación esencial, lo que permite a los modelos aprender a través de técnicas como el aprendizaje por refuerzo a partir del feedback humano (RLHF) y el ajuste fino supervisado (SFT).
En el ámbito de las aplicaciones de generación de texto a video, los modelos deben no solo crear contenido visualmente atractivo, sino también mantener una coherencia narrativa y un flujo natural a lo largo de todo el metraje. Elementos como el ritmo de los movimientos, la consistencia visual y la suavidad de las transiciones son fundamentales para lograr un contenido de calidad. Gracias a la segmentación y anotación precisas, los colaboradores humanos ofrecen un feedback minucioso sobre estos aspectos, ayudando a los modelos a entender qué hace que una secuencia de video generada resulte natural y auténtica.
Por otro lado, en la generación de texto a voz, comprender las sutilezas del habla humana, como las pausas entre frases o los cambios de tono emocional, depende de una retroalimentación detallada a nivel de segmentos. Este tipo de información granular es crucial para que los modelos logren producir un habla que suene natural, respetando el ritmo y la consistencia emocional esperados. Con la creciente integración de capacidades multimedia en los grandes modelos de lenguaje (LLM), el rol del feedback humano se hace aún más crítico, pues facilita la generación de contenido multimedia rico que cumpla con los estándares de calidad humana.
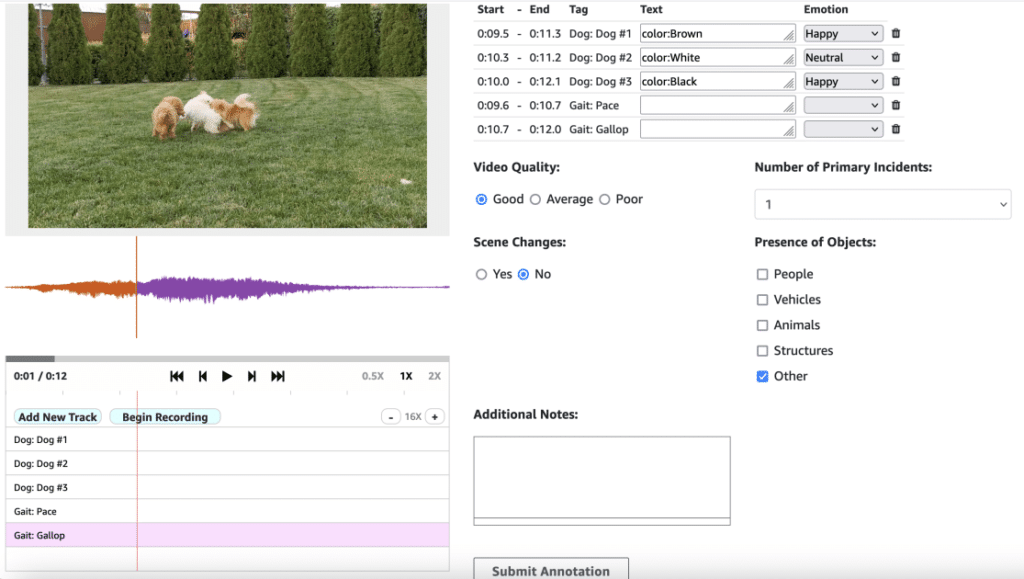
El desarrollo de modelos efectivos para la generación de audio y video enfrenta desafíos específicos, entre ellos la necesidad de que los anotadores identifiquen momentos precisos donde el contenido generado cumpla o no con las expectativas humanas naturales. En el caso de la generación de discurso, esto implica marcar puntos exactos de cambios de entonación, pausas antinaturales o variaciones inesperadas en el tono emocional. En la generación de video, los anotadores deben señalar fotogramas donde los movimientos se tornen bruscos, donde falle la consistencia de los objetos o donde los cambios de iluminación resulten artificiales.
La herramienta Amazon SageMaker Ground Truth permite integrar este feedback humano detallado directamente en el entrenamiento del modelo. A través de flujos de trabajo personalizados de anotación humana, las organizaciones pueden equipar a los anotadores con herramientas para segmentación de alta precisión, permitiendo que el modelo aprenda a partir de datos etiquetados por humanos y refinando su capacidad para generar contenido que se alinee con las expectativas humanas.
Este sistema de segmentación de audio y video proporciona una guía para implementar la infraestructura necesaria, crear una fuerza de trabajo de etiquetado interna y configurar el trabajo de etiquetado inicial. Utilizando Wavesurfer.js para la visualización y segmentación precisa de audio, se puede personalizar la interfaz para satisfacer necesidades específicas, abarcando tanto enfoques basados en consola como programáticos.
La calidad de los datos es vital para entrenar modelos AI generativos que produzcan contenido de audio y video con naturalidad y fluidez. El desempeño de estos modelos está directamente relacionado con la precisión y detalle del feedback humano obtenido mediante un proceso de anotación riguroso. SageMaker Ground Truth aborda desafíos comunes en este campo, ofreciendo funciones avanzadas como el zoom para facilitar la captura precisa de momentos cruciales que inciden en la percepción de calidad en los modelos de generación de discurso y video.
La incorporación de diversos servicios de AWS en este proceso de anotación sólida, incluyendo la distribución de contenido seguro a través de Amazon CloudFront, asegura una entrega eficiente de los componentes de interfaz de usuario. AWS Lambda ofrece funciones opcionales para enriquecer el flujo de trabajo, permitiendo adaptaciones flexibles sin modificar el proceso de anotación central.
Con esta solución de segmentación, las organizaciones pueden generar datos de alta calidad cruciales para el entrenamiento eficaz de modelos generativos de AI, mejorando aplicaciones como la síntesis de voz, la generación de videos o el reconocimiento de patrones de audio complejos. En esta era de contenido multimedia generado por AI, el feedback humano sigue siendo esencial para mejorar continuamente la calidad y autenticidad del contenido creado.













