En los últimos tiempos, hemos presenciado un avance sin precedentes en el ámbito de los modelos de lenguaje de gran escala (LLMs), impulsando a numerosas empresas a adoptar asistentes virtuales para optimizar tanto la atención al cliente como la eficiencia interna de sus equipos. Mediante la implementación de asistentes de chat basados en modelos de generación aumentada por recuperación (RAG), las organizaciones están empleando complejos LLMs para consultar documentos específicos y responder preguntas pertinentes a sus casos de uso.
Un avance notable en este panorama ha sido el desarrollo de modelos fundacionales multimodales, capaces de interpretar y generar texto a partir de imágenes, fusionando información visual con lenguaje natural. Sin embargo, estos modelos enfrentan la limitación de operar exclusivamente sobre la información con la que fueron entrenados.
En este contexto, Amazon Web Services (AWS) propone una solución innovadora usando los modelos de Amazon Bedrock, que permite crear un asistente de chat multimodal. Este asistente está diseñado para procesar tanto imágenes como preguntas, dando respuestas fundamentadas en documentos exclusivos de la organización. Un uso práctico de este modelo se observa en la industria minorista, donde puede potenciar la venta de productos o en el sector manufacturero para agilizar el mantenimiento y reparación de maquinarias.
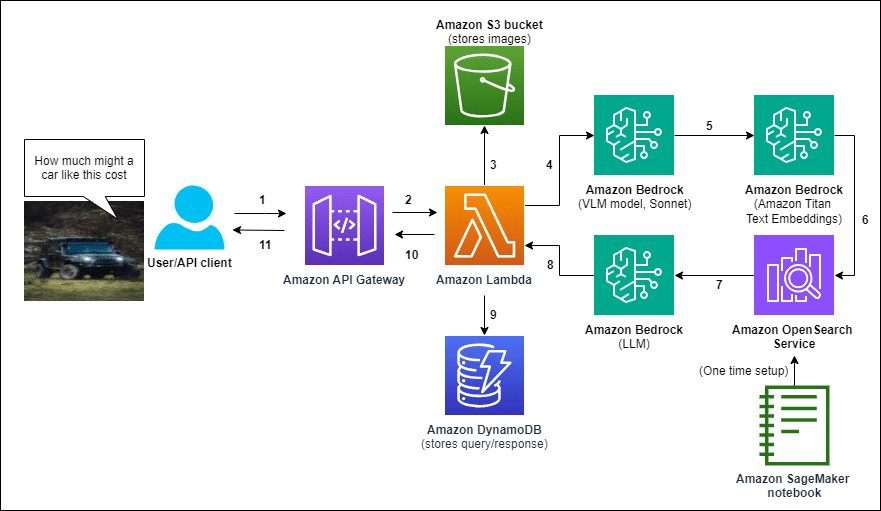
La implementación de esta solución por parte de AWS comienza con la creación de una base de datos vectorial, utilizando Amazon OpenSearch Service. Posteriormente, el asistente es desplegado mediante una plantilla de AWS CloudFormation. El proceso inicia cuando un usuario carga una imagen y formula una pregunta. Esta interacción es gestionada a través de Amazon API Gateway, dirigiéndose a una función de AWS Lambda que procesa la información. La imagen es almacenada en Amazon S3, permitiendo futuros análisis. La función Lambda coordina varias llamadas a modelos de Amazon Bedrock para describir textualmente la imagen, y convertir tanto la pregunta como la descripción en representaciones vectoriales, recuperando así datos relevantes de OpenSearch y generando una respuesta basada en los documentos hallados. Toda la información de la consulta y la respuesta es almacenada en Amazon DynamoDB, enlazadas con el ID de la imagen en S3.
Este sistema ofrece una ventaja significativa para sectores que requieren respuestas especializadas basadas en datos propios a partir de entradas multimodales. Un ejemplo ilustrativo es el mercado automotriz, donde usuarios pueden subir una imagen de un vehículo, formular consultas y recibir respuestas respaldadas por una base de datos de listados de automóviles, demostrando la adaptabilidad de esta tecnología en diferentes ámbitos.
La principal fortaleza de esta solución radica en su capacidad para entregar respuestas precisas y contextualizadas basadas en datos específicos, enriqueciendo la experiencia del usuario y elevando la eficiencia operativa. Asimismo, este enfoque presenta posibilidades de personalización y escalabilidad, permitiendo a las organizaciones ajustar el asistente a sus necesidades particulares y explorar nuevas formas de interacción entre humanos y máquinas.













