En un mundo donde la inteligencia artificial se está volviendo cada vez más esencial, la Generación Aumentada por Recuperación (RAG) se ha convertido en un componente crucial para perfeccionar la precisión de las respuestas generadas por los modelos de lenguaje de gran escala. La eficacia de RAG se basa en la calidad del contexto proporcionado al modelo, contexto que, de manera habitual, se obtiene de almacenes vectoriales según las consultas del usuario.
Una de las técnicas más efectivas para aumentar la relevancia del contexto es el filtrado de metadatos, que refina los resultados de búsqueda mediante un pre-filtrado del almacén vectorial basado en atributos de metadatos personalizados. Esto ayuda a reducir el ruido y la información irrelevante.
No obstante, la construcción manual de estos filtros representa un reto, sobre todo cuando se trata de consultas complejas o con muchos atributos de metadatos. Para superar estos desafíos, se pueden emplear modelos de lenguaje de gran escala mediante un enfoque innovador llamado filtrado inteligente de metadatos.
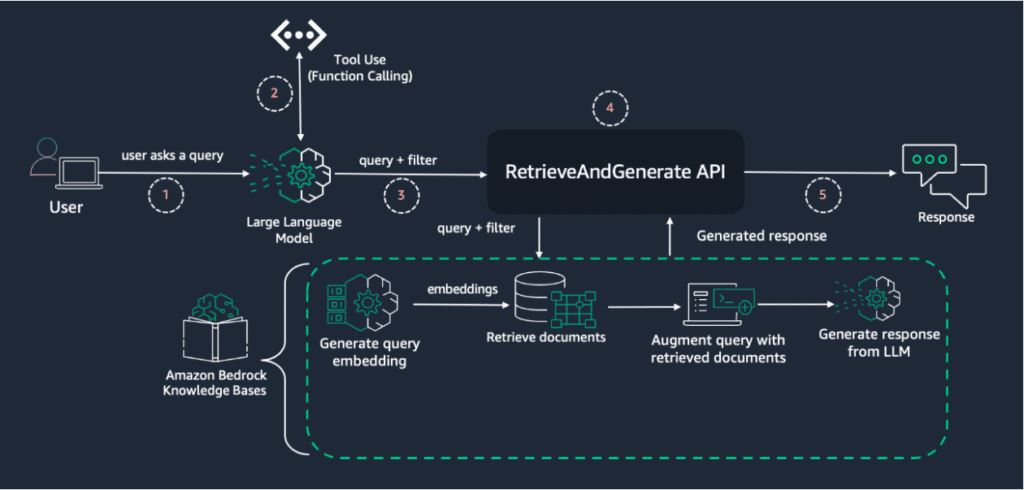
Amazon ha implementado este sistema a través de su servicio Bedrock, el cual permite utilizar modelos de lenguaje para derivar filtros de metadatos dinámicamente, basándose en consultas en lenguaje natural. Esto es posible gracias a herramientas de llamado de funciones, las cuales permiten a los modelos de lenguaje interactuar con funcionalidades externas, mejorando así la capacidad para procesar consultas complejas.
Amazon Bedrock, un servicio completamente gestionado, ofrece una variedad de modelos fundacionales de alto rendimiento de empresas líderes en inteligencia artificial a través de una única API. Destaca su característica de Bases de Conocimiento, que proporciona una capacidad RAG completamente gestionada, ahora mejorada con potentes capacidades de filtrado de metadatos.
La implementación de este filtrado dinámico puede significar una enorme mejora en las métricas claves de un sistema RAG: aumenta la relevancia y el recuerdo del contexto, así como la precisión de las respuestas. La integración de Amazon Bedrock y modelos de datos Pydantic para la validación y estructuración de datos permite extraer entidades y confeccionar filtros de metadatos que optimizan el proceso de recuperación de información.
El proceso empieza cuando una consulta del usuario es procesada por un modelo de lenguaje que extrae metadatos relevantes. Estos metadatos se utilizan para crear un filtro adecuado, mejorando así la relevancia de los documentos recuperados.
El filtrado inteligente a través de Amazon Bedrock no solo simplifica la construcción de estos filtros, sino que también facilita la creación de aplicaciones RAG más eficaces, que permiten consultas en lenguaje natural más intuitivas. De esta forma, las respuestas generadas se ajustan mejor a las necesidades del usuario, siendo más precisas y relevantes.













