Zyphra ha presentado ZAYA1-8B, un modelo de lenguaje de tipo Mixture-of-Experts diseñado para competir en razonamiento, matemáticas y programación con modelos abiertos de mucho mayor tamaño. La compañía lo vende con una idea muy directa: extraer más inteligencia de cada parámetro y de cada FLOP, en lugar de depender únicamente de escalar modelos cada vez más grandes y caros.
El lanzamiento tiene también una segunda lectura industrial. ZAYA1-8B se ha entrenado sobre infraestructura AMD, con GPUs Instinct MI300X, red AMD Pensando Pollara e infraestructura de IBM Cloud. En un mercado dominado por NVIDIA en entrenamiento e inferencia de Inteligencia Artificial, Zyphra intenta demostrar que hay margen para construir modelos competitivos sobre una pila alternativa, siempre que arquitectura, software y hardware se diseñen juntos desde el principio.
Un MoE de 8.400 millones de parámetros con solo 760 millones activos
ZAYA1-8B no es un modelo denso tradicional. Es un Mixture-of-Experts, una arquitectura en la que no todos los parámetros se activan en cada consulta. Según la ficha publicada en Hugging Face, el modelo tiene 8.400 millones de parámetros totales, pero solo 760 millones de parámetros activos durante la inferencia. Esa diferencia es relevante porque permite aumentar la capacidad total del sistema sin pagar siempre el mismo coste computacional que tendría un modelo denso equivalente.
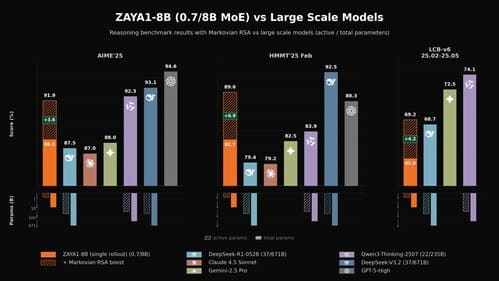
Zyphra sostiene que ZAYA1-8B ofrece un rendimiento especialmente fuerte en razonamiento largo, matemáticas y código. En sus comparativas, el modelo obtiene 89,1 puntos en AIME 2026, 71,6 en HMMT Feb. 2026 y 65,8 en LiveCodeBench v6, con resultados que lo sitúan cerca o por encima de modelos abiertos bastante mayores en varias pruebas. Como ocurre con cualquier benchmark publicado por el propio desarrollador, estos datos deben leerse como una referencia inicial, no como una verdad definitiva sobre todos los usos posibles.
El interés del modelo está precisamente en esa relación entre tamaño, coste y resultado. Si un sistema con menos de 1.000 millones de parámetros activos puede resolver tareas de razonamiento o programación con un nivel competitivo, su despliegue puede ser más barato, más rápido y más fácil de llevar a infraestructuras privadas, servidores propios o incluso dispositivos locales. La propia ficha de Hugging Face señala que, por su tamaño total relativamente reducido, ZAYA1-8B puede desplegarse en escenarios locales de LLM.
Markovian RSA: razonar más tiempo sin disparar la memoria
Junto al modelo, Zyphra ha introducido Markovian RSA, una metodología de cómputo en tiempo de prueba que combina generación paralela de trazas y razonamiento dividido en fragmentos de contexto fijo. Dicho de forma sencilla, el sistema genera varias rutas posibles de razonamiento, conserva solo segmentos relevantes y los vuelve a combinar en nuevas rondas, sin que el contexto crezca de forma indefinida.
La empresa afirma que esta técnica permite razonamiento potencialmente muy largo con un coste de memoria acotado. En su explicación técnica, Zyphra indica que Markovian RSA aprovecha la generación paralela para usar mejor el batching y mantiene limitado el tamaño del contexto mediante el troceado markoviano. En pruebas internas, la compañía asegura que esta metodología mejora especialmente el rendimiento en problemas matemáticos difíciles.
El planteamiento encaja con una tendencia clara en la IA generativa. Durante los últimos años, buena parte del avance se ha apoyado en entrenar modelos más grandes. Ahora crece el interés por técnicas que permitan mejorar las respuestas dedicando más cómputo en el momento de resolver una tarea concreta. Ese cómputo adicional puede servir para explorar varias soluciones, revisar pasos intermedios o contrastar respuestas candidatas antes de ofrecer un resultado final.
Zyphra asegura que, con configuraciones extendidas de Markovian RSA, ZAYA1-8B puede acercarse a modelos frontera abiertos en determinados benchmarks matemáticos e incluso superar a algunos modelos más grandes en APEX-shortlist bajo cómputo ampliado. Es una afirmación ambiciosa y conviene separarla del uso cotidiano: razonar con millones de tokens por problema puede ser útil en evaluación o tareas muy especializadas, pero no necesariamente representa el coste real de una aplicación empresarial estándar.
AMD gana un argumento frente al dominio de NVIDIA
El lanzamiento de ZAYA1-8B también funciona como escaparate para AMD. Zyphra afirma que el modelo se preentrenó por completo en hardware AMD, usando un clúster de 1.024 GPUs MI300X con interconexión AMD Pensando Pollara. Esta base continúa el trabajo de ZAYA1-base, que AMD presentó en noviembre de 2025 como una prueba de entrenamiento a gran escala sobre una plataforma integrada de GPUs Instinct, red Pensando y software ROCm.
El antecedente técnico es importante. AMD explicó entonces que el entrenamiento de ZAYA1-base se realizó junto a Zyphra e IBM Cloud y que la memoria de 192 GB HBM de las MI300X permitió simplificar la estrategia de paralelismo. También destacó el uso de ocho NICs AMD Pensando Pollara de 400 Gbps por nodo, con 3,2 Tbps de ancho de banda por nodo.
Para AMD, casos como este sirven para reforzar un mensaje que lleva tiempo intentando colocar en el mercado: sus aceleradores no solo son una alternativa para inferencia, sino también para entrenamiento de modelos de gran escala. El dominio de NVIDIA sigue siendo muy fuerte por hardware, software, comunidad, librerías y disponibilidad, pero los clientes de IA buscan segundas fuentes por coste, suministro y negociación. Un modelo abierto entrenado de extremo a extremo sobre AMD ayuda a dar credibilidad a esa conversación.
Para Zyphra, la apuesta por eficiencia tiene sentido comercial. La compañía puede ofrecer ZAYA1-8B como endpoint serverless en Zyphra Cloud y, al mismo tiempo, publicar los pesos en Hugging Face bajo licencia Apache 2.0. Esa combinación permite probar el modelo sin instalar nada, pero también descargarlo, auditarlo y adaptarlo en entornos propios, algo cada vez más demandado por empresas que no quieren depender solo de APIs cerradas.
El modelo incorpora varias decisiones técnicas orientadas a eficiencia. Zyphra cita Compressed Convolutional Attention, un router de expertos basado en MLP para mejorar la estabilidad del enrutamiento y escalado residual aprendido para controlar el crecimiento de normas residuales a lo largo de la profundidad. En la fase posterior al entrenamiento, la compañía combina ajuste supervisado con una cascada de aprendizaje por refuerzo en cuatro fases, centrada primero en razonamiento matemático y puzzles, después en currículos adaptativos, código y matemáticas a gran escala, y finalmente en calidad conversacional e instrucciones.
La pregunta ahora es cómo se comportará ZAYA1-8B fuera de los gráficos del fabricante. Los benchmarks de razonamiento, matemáticas y código son útiles, pero no sustituyen pruebas independientes en casos reales: agentes de software, asistentes internos, análisis documental, herramientas para desarrolladores o despliegues locales con restricciones de coste. La licencia Apache 2.0 facilita precisamente que la comunidad y las empresas lo sometan a esa revisión.
ZAYA1-8B no pretende ganar la batalla por tamaño. Su argumento es otro: si la IA va a estar en más aplicaciones, más dispositivos y más infraestructuras privadas, la eficiencia por parámetro puede ser tan importante como el número total de parámetros. En ese terreno, los modelos MoE pequeños, abiertos y entrenados sobre pilas alternativas a NVIDIA pueden convertirse en una parte cada vez más interesante del mercado.
Preguntas frecuentes
¿Qué es ZAYA1-8B?
ZAYA1-8B es un modelo de lenguaje Mixture-of-Experts desarrollado por Zyphra, con 8.400 millones de parámetros totales y 760 millones de parámetros activos durante la inferencia.
¿Por qué Zyphra habla de “intelligence density”?
La compañía usa esa expresión para destacar que el modelo busca obtener mucho rendimiento con pocos parámetros activos, en lugar de depender solo de aumentar el tamaño total del modelo.
¿Qué hardware se usó para entrenar ZAYA1-8B?
Zyphra afirma que el modelo se entrenó sobre infraestructura AMD, con GPUs Instinct MI300X, red AMD Pensando Pollara e IBM Cloud.
¿ZAYA1-8B es un modelo abierto?
Sí. Los pesos están disponibles en Hugging Face y el modelo se ha publicado bajo licencia Apache 2.0, según Zyphra y la ficha oficial del modelo.













